고정 헤더 영역
상세 컨텐츠
본문
1. An Image is Worth 16x16 Words : Transformers for Image Recognition at Scale
https://arxiv.org/pdf/2010.11929
ICLR 2021
- 배경 및 목적 : Transformer 는 NLP에서 표준이지만, 컴퓨터 비전에서는 응용이 제한적, 전통적으로 Vi는 CNN과 함께 attention을 사용
- 주요 발견 :
- CNN에 의존하는 것은 필요하지 않으며, 이미지 Patch를 직접 사용하는 순수 Transformer가 이미지 분류 작업에서 더 잘 작동할 수 있음
- 충분한 데이터를 pre-training한 후 여러 중소 규모 이미지 인식 밴치마크에서 ViT는 뛰어난 성능을 최신 CNN과 비교하면 보임
- 성과 : ViT는 큰 데이터 셋 (14M ~ 300M 이미지)에서 훈련되며 ImageNet, CIFAR-100 같은 표준 데이터셋에서 높은 정확도를 기록함
- ImageNet 88.5%, CIFAR-100 94.55%
- 결론 : 대규모 훈련이 Inductive Bias보다 성능에 더 큰 영향을 미친다는 사실을 발견
2. Related Works
Transformer 기반의 비전 모델이 대규모 데이터에서 CNN보다 경쟁력을 가질 수 있음을 입증
| Model Overview

1. 2D 이미지를 "고정된 크기"의 Patch 로 변환
- Base Transformer : 입력 token간의 관계 학습
- 문제점 : 만약 이미지에서 pixel = token으로 하게 된다면, 너무 많은 연산량 필요
- 224*224 image, 50,000개 이상의 token 생성, 50,000^2의 attention 연산 수행 (O(n^2)) >> not good...
- 문제점 : 만약 이미지에서 pixel = token으로 하게 된다면, 너무 많은 연산량 필요
- Solution : 입력 token = patch (n pixels * n pixels)
- 예시) 이미지를 3*3으로 분할, 해당 예시의 patch size는 32*32
- 하나의 작은 정사각형 = patch
- Transformer에서 기본 단위를 token로 사용하듯이, 이미지에서는 기본 단위를 token 대신 patch로 사용
- 다만 token과 patch를 혼용해서 사용함, 두 단어의 의미는 "동일함"
2. 각 patch들을 linear embedding함
- 예시) 9개의 patch를(token) 직선으로 두는 것
- 이렇게 되면 총 3*3 = 9개의 patch (token) 생성됨
- Linear embedding을 나이브하게 이해하자면, 고차원 데이터를 저차원으로 축소이전 매핑단계
3. 각 flattened patch를 linear projection하여 1D로 차원 축소
- Linear projection은 한 벡터를 다른 벡터 공간에 표기하는 것, 마치 정사영
- 예시) 각 token의 차원은 3*32*32 = 3072 (total pixels per patch)
- image에서 차원은 pixel의 개수
- image는 R,G,B 3개의 채널을 갖고 있음 -> 3
- patch의 size는 32*32 -> 32*32
- 따라서 전체 pixel의 개수는 3*32*32


- 위 그림 figure 7 left의 결론
- 저차원으로 변환해도 이미지의 중요한 특징을 유지하면서 표현할 수 있음
- 왜 저차원으로 변형했을까?
- 고차원 token(patch)를 사용하게 되면 계산량이 너무 많음
- 그래서 저 이미지가 왜?
- 저차원으로 표현해도, 원본 patch(token)을 잘 표현하고 있음을 주장하기 위해서 사용
- 고차원 -> 저차원 변환 filter 그림, 저 filter들이 이미지의 주요 특징들을 잘 추출하며 저차원 변환 하고 있음을 보여줌
- 맨 윗줄은 가로 세로 선들, 중간은 rgb, 아래는 복잡한 패턴
- 왜 저차원으로 변형했을까?
- 저차원으로 변환해도 이미지의 중요한 특징을 유지하면서 표현할 수 있음
4. Positional Embedding(PE) 실행
- 이전 Transformer에서 PE를 실행한 사유와 동일함
- Transformer의 PE : Token들에는 순서 정보가 없어서 PE를 추가하여 Token들간의 순서 정보 주입
- 동일하게, 이미지들도 이미지들간의 순서 정보가 필요하여 embedding 된 patch(token)에 PE 주입
- Transformer의 PE : Token들에는 순서 정보가 없어서 PE를 추가하여 Token들간의 순서 정보 주입
- 예시) 보라+분홍 타원, Patch + Position Embedding
여기까지가 우측 Transformer의 분홍색 Embedded Patches의 진입 단계
5. Transformer의 Encoder에 입력하여 차원 축소 (3072 -> 768)
- 이 부분이 논문의 시사점
- CNN보다 순수 Transformer가 이미지 classification task에 유리함을 보여주는 점
- Transformer의 실제 입력 sequence = patch (token) 의 개수 N
- 예시) 비교 CNN을 이용해서 차원 축소 (3072 dimension -> 768 dimension)
- CNN
- 1 patch (token)의 dimension은 3072
- 32*32 Conv, stride 32, padding 0
- in_channels = 3, out_channels = 768
- 필요한 param 개수 = 3072*768 = 2.36M
- CNN
3. Method
| Vision Transformer (ViT) Equation
Model overview와 연속된 내용 + 수식 추가 정리

(1) Transformer Encoder의 최종 입력 생성

- z_0 : Transformer 모델에 최종적으로 들어가게 되는 생성된 입력 벡터
- x_class : 분류를 위한 특별한 학습 가능한 토큰, 예시의 작은 타원들 중 맨 앞에 있는 것
- x_i^p E : 클래스 정보, 여러 패치의 임베딩을 결합
- E : Patch embedding을 생성하기 위한 행렬 (E = Linear projection matrix)
- P : Patch의 가로, 세로 크기 (32)
- x_p^1 : Encoder p층의 1번째 토큰, 단순 입력값 (learnable x)
- E : Patch embedding을 생성하기 위한 행렬 (E = Linear projection matrix)
- E_pos : 위치 임베딩 행렬, 위치 정보를 제공
- 차원 중 N이 아닌 N+1 인 이유
- N : 패치의 개수
- +1 : 특별한 학습 가능한 토큰 For 분류 (x_class)
- 차원 중 N이 아닌 N+1 인 이유
(2), (3) Transformer Encoder의 L개의 층에 순차적으로 입력 전달



- l : Transformer에서 Encoder 층의 개수
(4) 최종 출력 생성 : Encoder의 마지막 층 가장 맨 처음 토큰 (분류 토큰) Layer Normalization

- LN : Layer Normalization
- z^0_L : Transformer의 마지막 레이어에서 class 토큰의 출력
- 간단한 예시 z^0_L-1 토큰이 Encoder - L의 입력으로 들어오고 있는 상황
- 0 : 입력 시퀀스 중 가장 앞에 있는 0번째 토큰
- L-1 : Encoder의 L-1층
- 간단한 예시 z^0_L-1 토큰이 Encoder - L의 입력으로 들어오고 있는 상황
| Inductive bias

- Inductive Bias : 귀납적 편향
- 모델이 학습할 때 사전에 가지고 있는 지식이나 가정, 즉 데이터를 학습하기 전에 이미 내재된 구조적 특징이나 패턴을 모델이 얼마나 활용하는가
- 그러니.. 모델이 특정 방식으로 학습하도록 "선천적으로 유리한 구조를 가지는지 여부"
- CNN의 Inductive Bias : 적은 데이터셋에서도 좋은 성능을 보임
- Locality (지역성)
- 필터가 작은 영역 (local patch) 에서 연산을 수행하므로, 주변 픽셀 간의 관계를 자연스럽게 학습
- Translation Equivariance (변환 불변성)
- 필터가 이미지를 이동 (translation) 해도 같은 특징을 감지할 수 있도록 설계됨
- 2D Spatial Structure (2D 공간 정보 유지)
- 필터가 이미지의 공간 구조를 보존하면서 학습
- Locality (지역성)
- ViT의 Inductive Bias : CNN보다 훨씬 적음 > 적은 데이터 Overfitting, 대량의 데이터는 오히려 유연함
- Self-Attention : global함, 모든 patch간의 관계를 학습해야 함
- MLP만 Local
- 2D Spatial Structure 거의 사용되지 않음
- 다만, Spatial relations (위치 정보)은 모델 초기 단계에서 Patch로 나눌 때 + fine-tuning 시 PE 때 포함되어 있음
- 이외에는 모든 위치 정보, 즉 공간적 관계는 학습을 통해 배워야 함
- 2D 정보가 사전에 내장되지 않음
- CNN은 Filter를 통해 이미지 구조를 자동으로 인식하지만, ViT는 이를 직접 학습해야 함
- Self-Attention : global함, 모든 patch간의 관계를 학습해야 함
1. ViT는 공간적인 정보를 직접 학습해야 하므로 (구조적으로 그렇게 설계됨-Only PE, patch, Inductive Bias ↓) 적은 데이터에서는 불리
2. 이와 달리 CNN은 구조적으로 설계가 이미지의 공간적 구조를 자동으로 학습되도록 설계되어 적은 데이터에서 유리
| Hybrid Architecture

- 사실 이 내용이 뭐라 요약해야할지모르겠다!2
| Fine-Tuning And Higher Resolution

- ViT는 보통 대규모 데이터셋에서 학습한 후, 작은 데이터 셋에서 Fine-Tuning함
- Fine-Tuning 시, 원래 학습했던 prediction head는 제거하고 새로운 zero-initialized DxK feedforward Layer 추가함
- 해상도를 높여 학습하는 것이 pre-training보다 더 좋은 성능을 낼 때가 많음
- 하지만 해상도를 높이면, patch size는 그대로이지만 patch의 개수가 많아져서 sequence length of Transformer은 증가
- Transformer는 길이가 다른 입력도 처리할 수 있지만, 기존에 학습했던 "PE"가 엉킬 수 있음
- 간단히 생각해보면, Transformer Encoder로 들어가는 token의 개수가 늘어남 -> 이로 인해 각 token에 해당하는 pre-training PE와 고해상도의 PE 값은 의미하는 바가 달라짐
- 이 문제를 해결하기 위해 2D Interpolation이 사용함
- 이 내용이 무엇인지는 언젠가 찾을 예정... 지금은 보류...
3. 실험 결과 및 분석
| SetUp
- model : ResNet, Vision Transformer(ViT), hybrid model
- dataset : ILSVRC-2012 ImageNet 데이터셋(1.3M 이미지, 1k 클래스) 및 그 상위집합인 ImageNet-21k(14M 이미지, 21k 클래스), JFT(303M 이미지, 18k 클래스)를 포함
- Comparison to State of the Art : ViT model은 최신 CNN 모델과 비교해서 성능이 뛰어남
- Pre-training Data Requirements : ViT는 JFT-300M과 같은 대형 데이터셋에서 잘 작동
| Model Variants

- ViT-L/16 = Large 모델에 16x16 patch size를 갖고 있음
- Baseline CNN : modified ResNet = ResNet (BiT)
- 단, batch normalization을 group normalization으로 교체 & standardized convol
- Hybrid (patch size 1x1)
- ResNet50 의 stage 4 output 사용
- stage 4 제거 & stage 3 확장 사용 -> sequence 길이 4배 증가, 연산량 증가
| Training & Fine-tuning

| ViT와 ResNet 성능 비교 : 다양한 크기의 데이터셋에서 성능 비교 (속도추가할것)
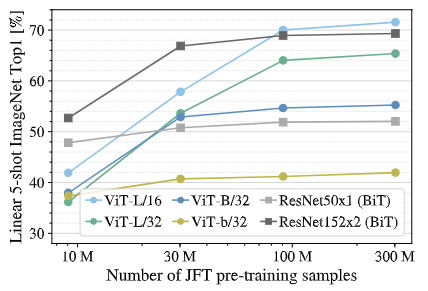
- 평가 기준 : Few-shot Linear Accuracy 기준 (Fine-Tuning 없이 일부 데이터만 이용)
- 작은 데이터셋 (9M) : ViT < ResNet
- 중간 데이터셋 (30M) : ViT = ResNet
- 큰 데이터셋 (90M+) : ViT > ResNet
1. 데이터셋 크기가 작을 때, CNN보다 ViT의 성능이 떨어짐
- Inductive Bias 차이 : CNN은 Locality와 Translation Equivariance를 선천적으로 학습
> 적은 데이터에서 일반화 가능
- Overfitting 문제 : ViT는 데이터에서 직접 패턴을 학습해야 하므로 쉽게 Overfitting됨
> CNN은 Convolution filter를 통해 일반적인 특징을 잘 잡아내지만, ViT는 강한 사전 정보 없이 데이터에서 패턴을 찾아야 하므로 데이터가 부족하면 성능이 떨어짐
2. 대규모 데이터셋으로 Pre-train하면 ViT는 CNN을 뛰어넘음
- 충분한 데이터가 있으며 ViT는 직접 패턴을 학습할 수 있음
- Self-Attention의 장점 : CNN은 Local filters (국소 필터) 로 학습하지만, ViT는 Global하게 (self-attention) 학습할 수 있음
> 큰 데이터셋에서 ViT가 더 깊이 있고 다양한 패턴을 학습할 수 있어 성능이 뛰어남
| ViT : 데이터셋 크기 증가에 따른 성능 변화 (내용추가)

'AI' 카테고리의 다른 글
| [논문리뷰] EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction (0) | 2025.02.20 |
|---|---|
| [논문리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2025.02.19 |
| [논문리뷰] Segment Anything (0) | 2025.02.18 |
| [용어정리] Attributes of Connections within Layer - hidden states (25.2.17) (0) | 2025.02.17 |
| [용어정리] Inference란 (25.2.17) (0) | 2025.02.17 |




