AI
[개념정리] Distributed Training
마농농
2025. 2. 25. 19:32
https://www.youtube.com/watch?v=tiAZUme2ST0

- 이전 내용까지는 inference를 가속화 하는 방법에 대해 다룸
- 예로, pruning, quantization, knowledge distillation..
- 이번 내용은 training을 더 빠르게 만드는 방법에 대해 다룰 예정
1. Background and motivation


- 더 높은 정확도를 위해서는 더 많은 연산량이 필요함
- 시간이 지날수록 모델 사이즈는 커지고 있음
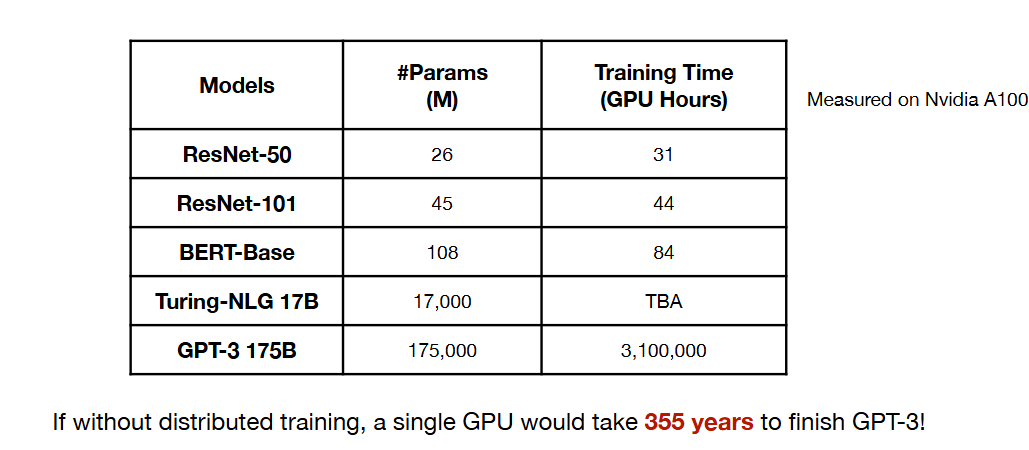
- gpu 하나로는 training을 감당할 수 없음 > 시간이 너무 오래 걸림
- 하지만 gpu가 여러 개라면 훈련 시간을 대폭 줄일 수 있음
- GPU 예 : V100, A100, B100
- More gpu,, more design cycles..
2. Parallelization methods for distributed training
1) Data Parallelism
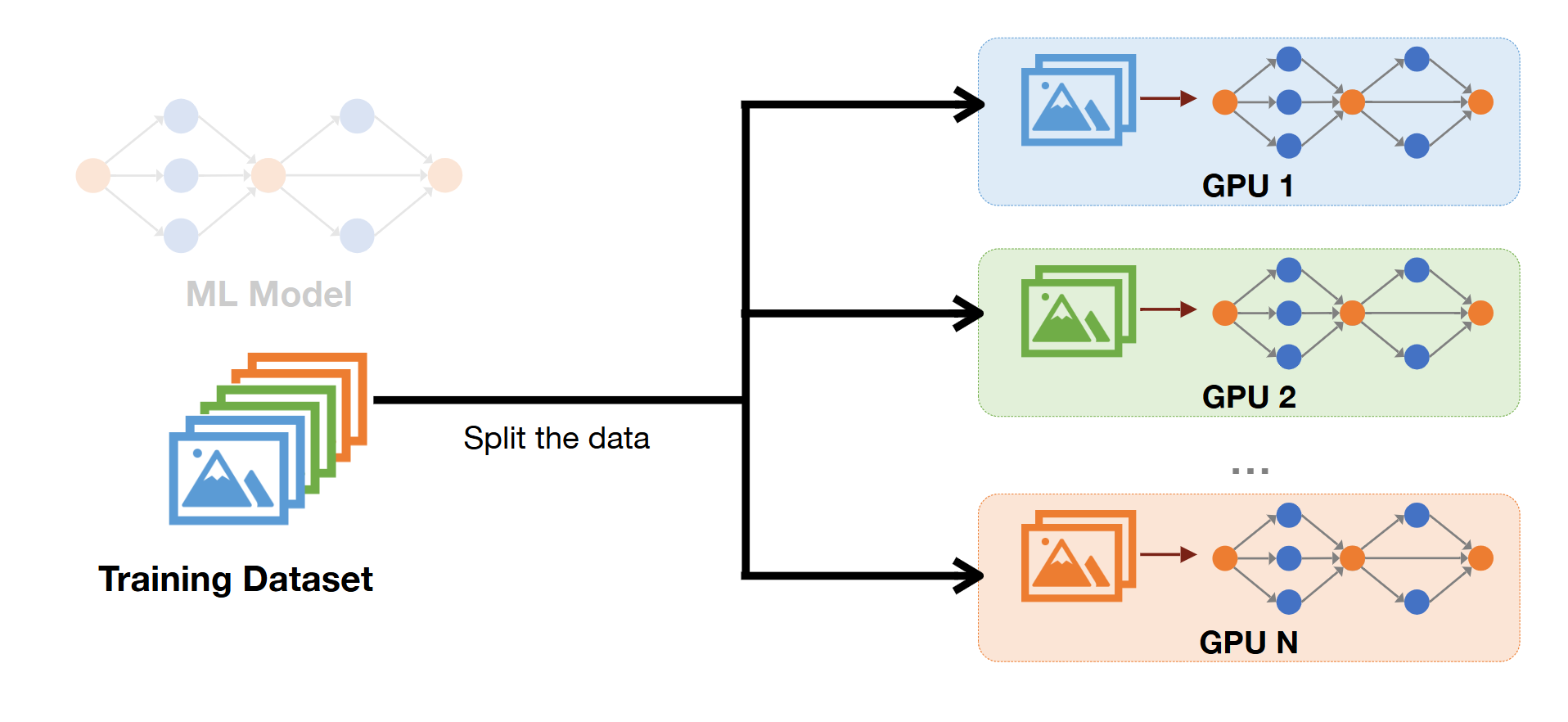

- spliting data > each gpu sharing same model
2) Pipeline Parallelism
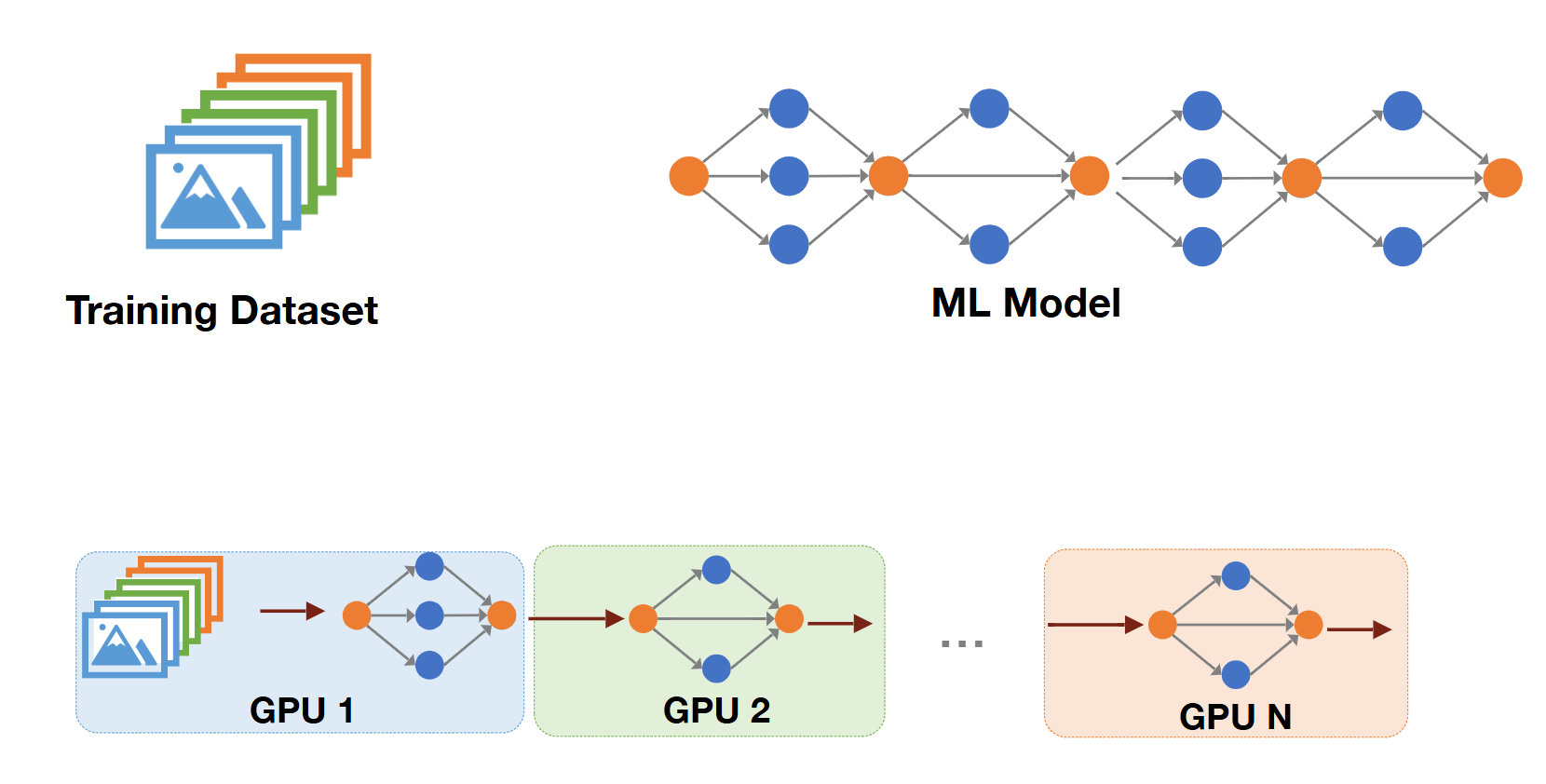
- sharing the same dataset, spliting the model
3) Tensor Parallelism

- spliting the layer
- also shring the same data
4) Sequence Parallelism
- 작년 강의에 포함되어 있지 않는 새로운 내용
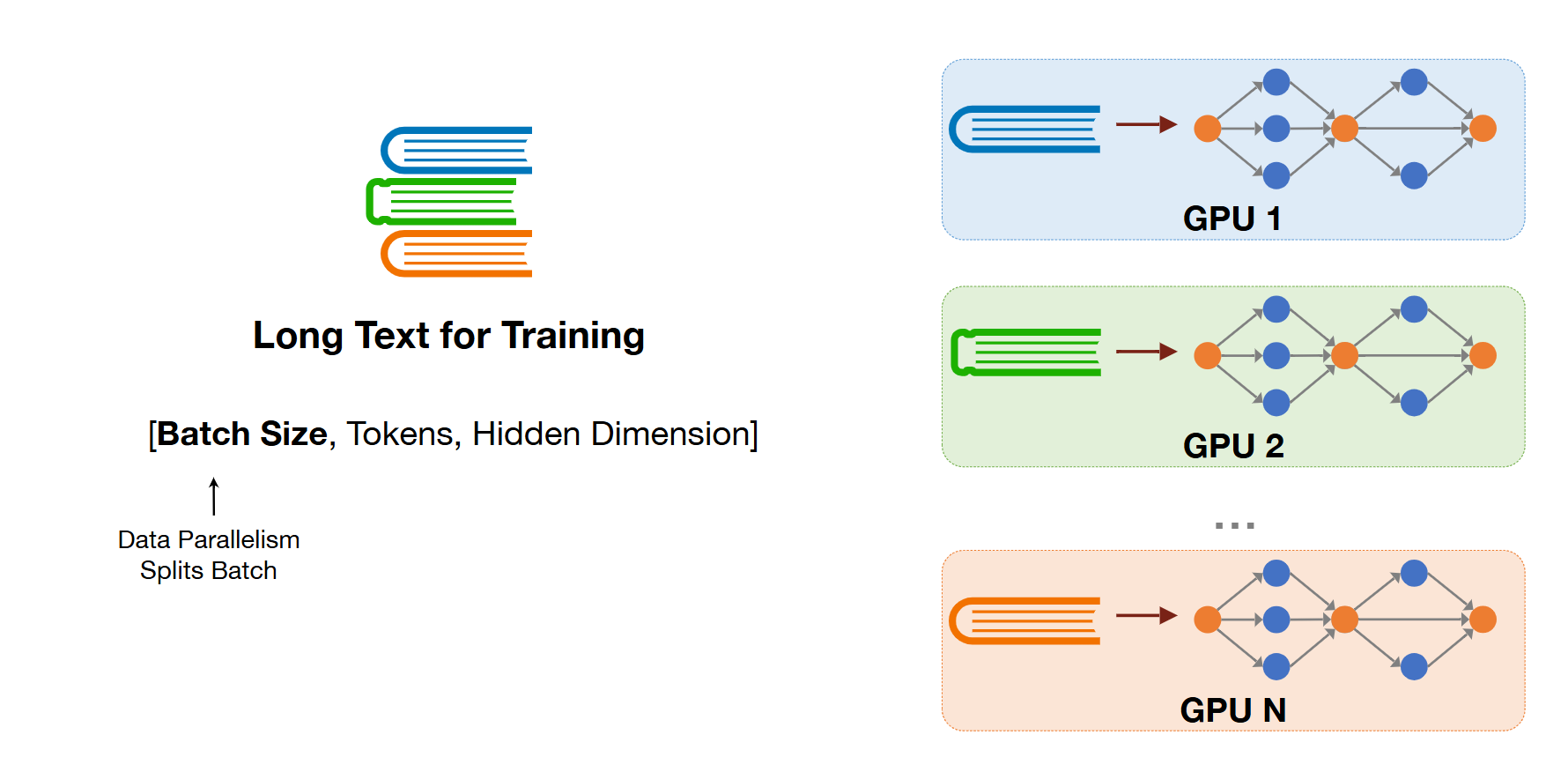
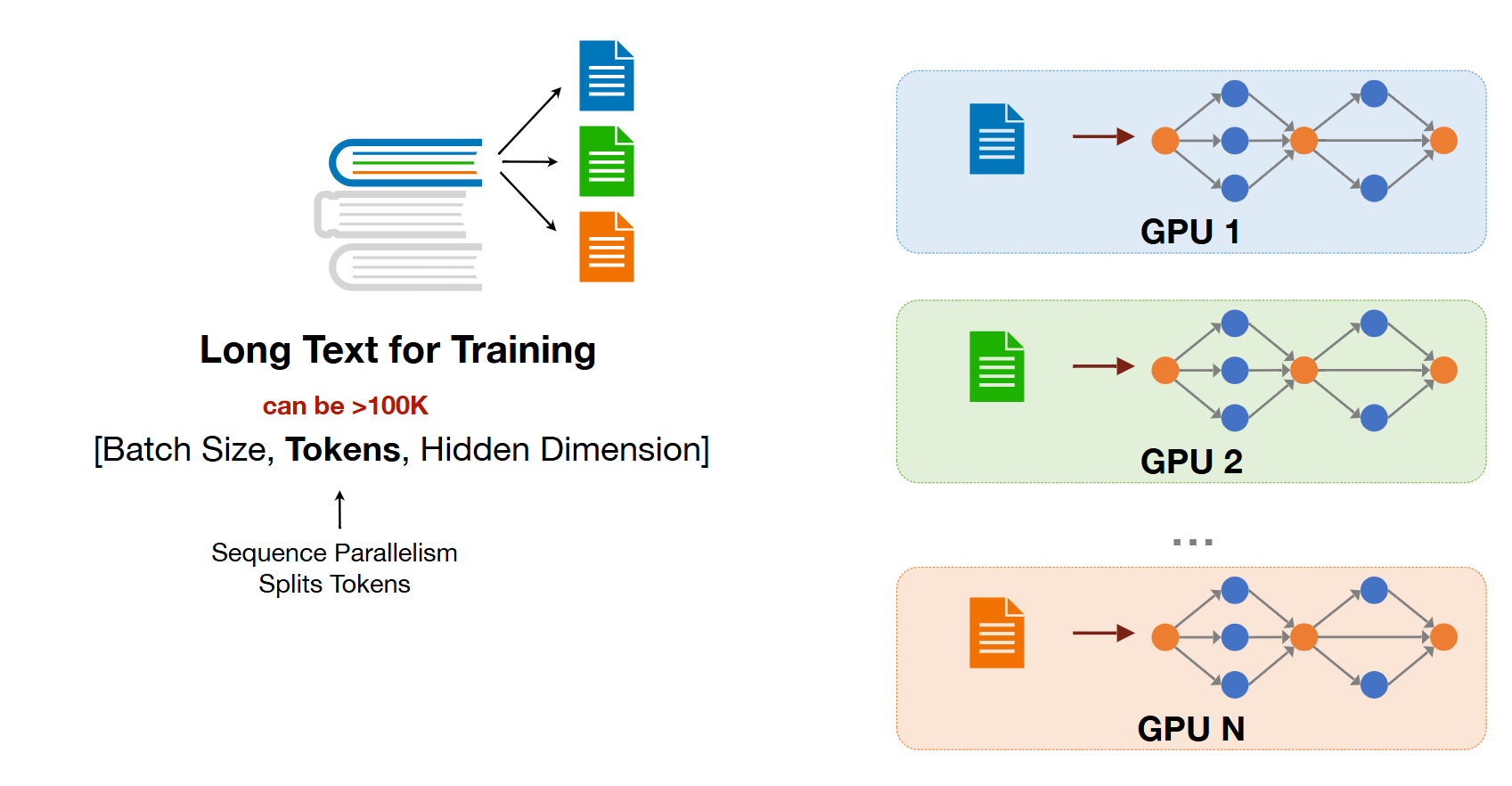
- batch dimension : data parallelism
- spliting the book
- token dimension : long sequence to short sequence
- data에서 또 data를 자르는 것,, nlp의 sequence가 too long한 점으로부터 착안된 것 같아보임
3. Data Parallelism

- centralization approach, 더 이상 사용하지 않는 방법
- 그림 설명
- 4명의 workers 로부터 서버가 데이터를 받아서(centralization) gradient를 update함


- 모델 복제
- 각 worker는 model을 가져옴
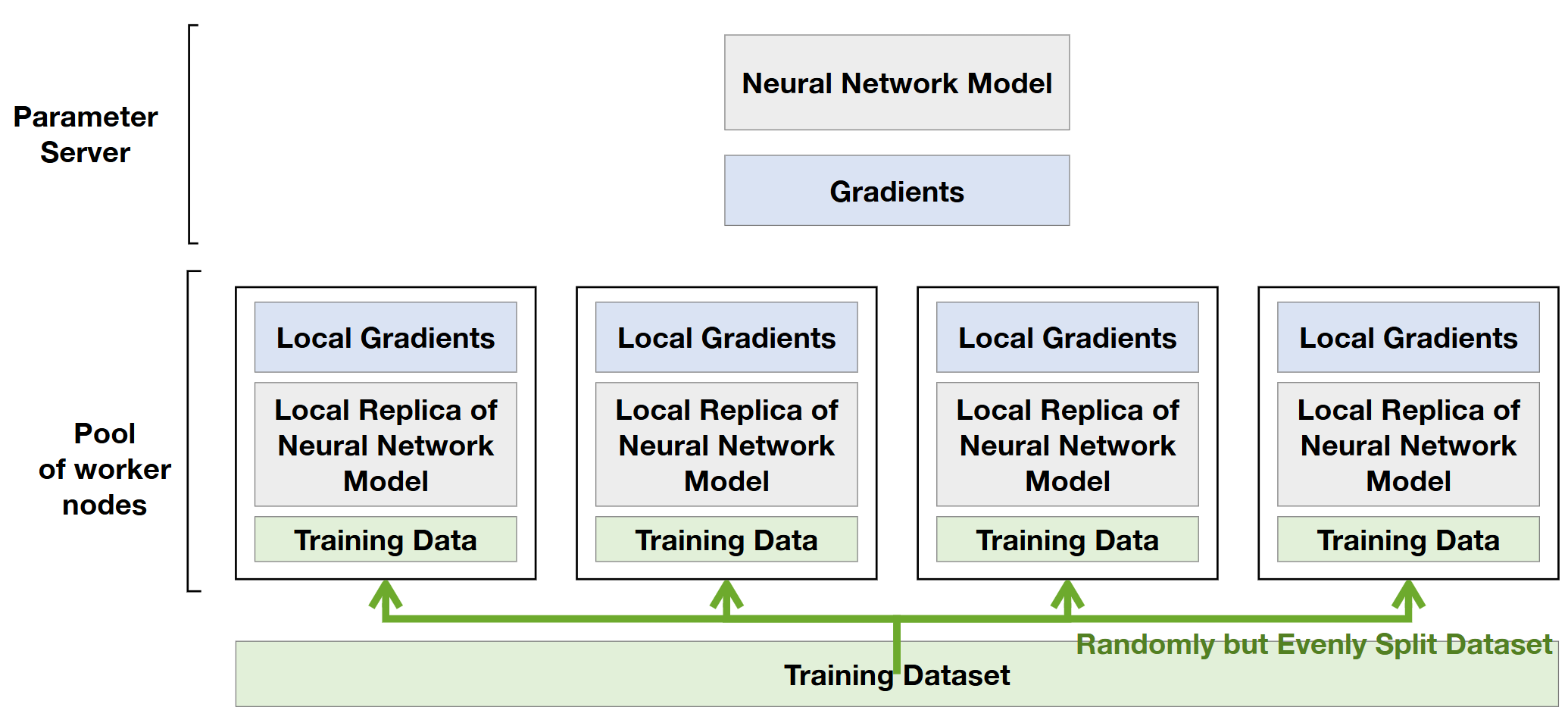
- data에는 weight, activation

- spliting된 dataset 사용 = 4 workers 는 서로 다른 dataset을 사용해서 training
- 따라서 각 model의 local gradient는 다름

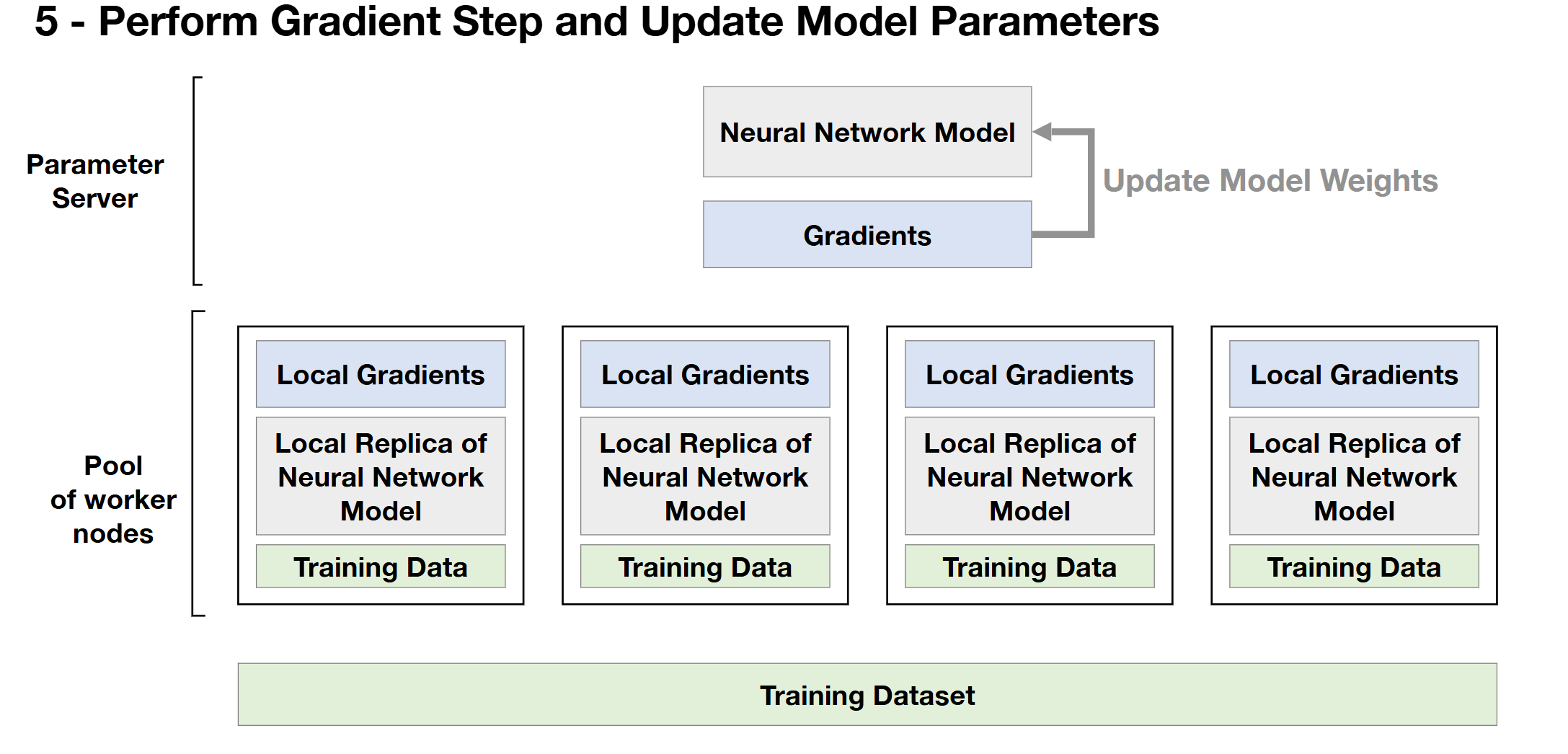
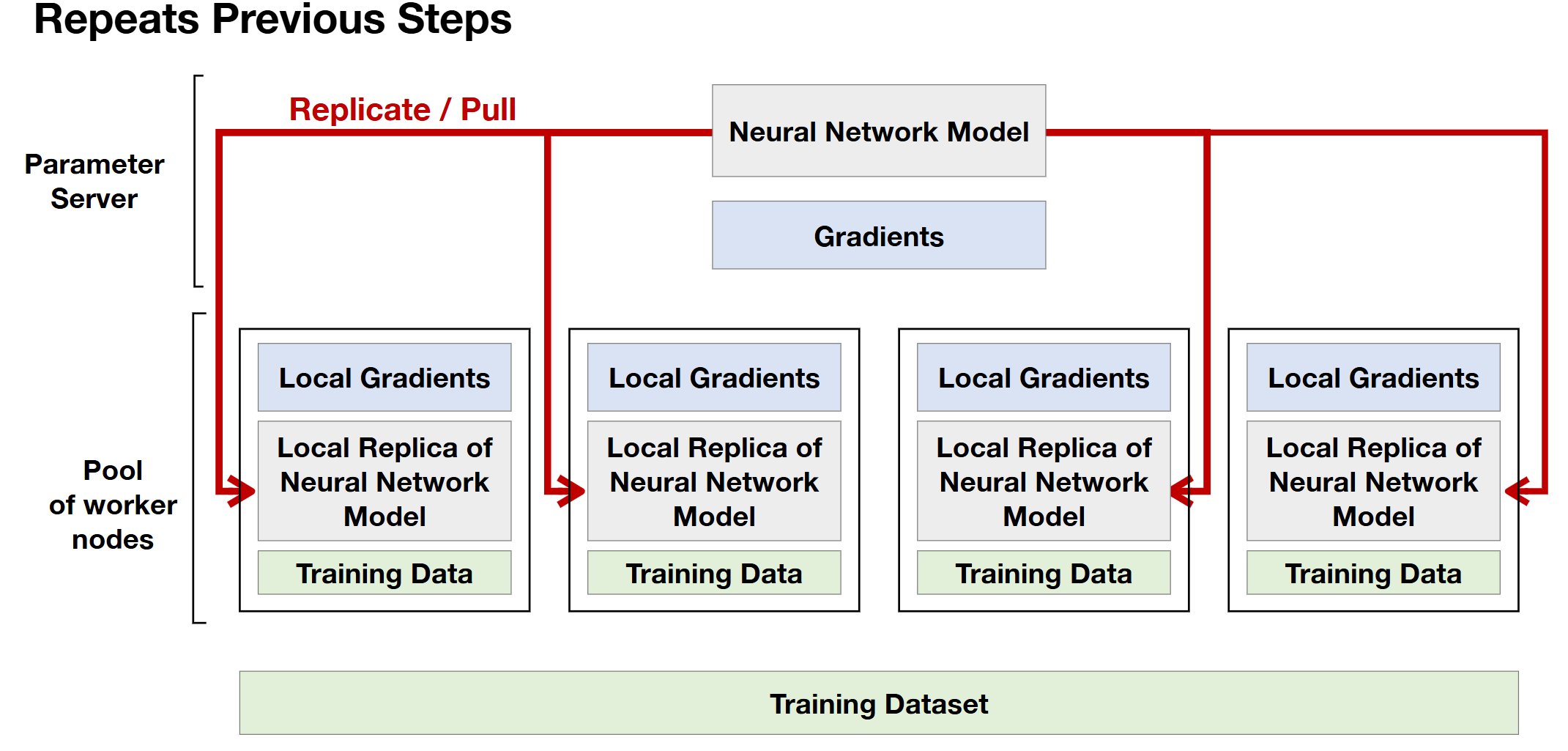


- 2개의 synchronize steps : 빨간 박스 (each worker, server)
4. Communication Primitives
- saving communication overheads
- 해당 내용은 추후 논문과 함께 정리할 예정.